
You can’t fix what you don’t see
Data path observability is the ability to see and understand the data flow from the originating request source, to the backend cloud infrastructure. It includes being able to see where the data is coming from, where it is going, and how it is being used. An important byproduct of this level of granular observation is the power to understand user behavior, by collecting and analyzing live data sets. By using the data to understand how users (potential customers) are interacting with your digital presence, brands can generate prescriptions for improvements to enhance performance and security. For example, let us look at how to take a user data set over a week to analyze for checkout conversions against subsets of page load times.
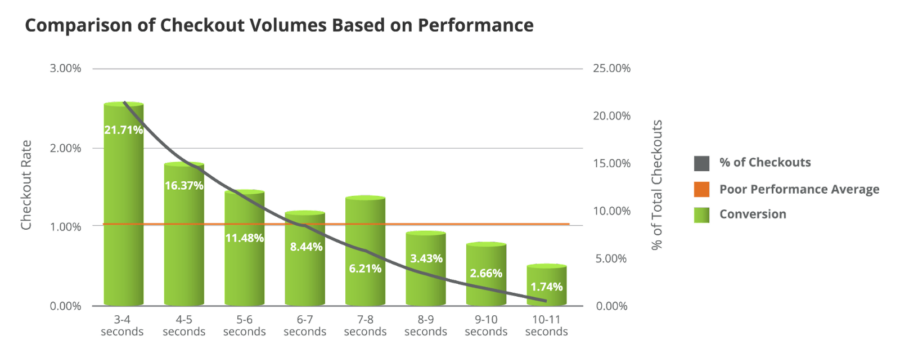
The X-axis represents the % of total checkout volume, while the Y-axis shows cohorts of page load time in one-second intervals. Keep an eye on the red line, which displays the industry threshold for what is considered a poor performance average for the total number of checkouts.
Checkouts, as a result of page load times under 4 seconds, represent around 32% of all checkouts which indicates that when the site’s performance and underlying infrastructure is consistently meeting or exceeding customer expectations, this results in a positive user experience and high conversion rates.
Checkout volume dramatically decreases second over second as page load times increase, eventually down to single digits. This is where the business needs to prioritize site optimization measures to improve the user experience and maximize conversion rates.
Great, you showed me there’s a problem…now what?
This looks like an application efficiency issue. Maybe a code improvement issue? Perhaps caching improvements will help. Maybe your hosting provider’s hardware cannot keep up. Possibly a combination? Now tickets are flying around between CDN, security, hosting, agency, ecommerce platform, third party integrations, the list goes on…sound familiar?
Remember, the foundation of an Intelligent CloudOps strategy is to observe data paths, but its superpower is using that traffic data, the user analytics, and other performance data at each layer, from content delivery to origin performance metrics, to make informed decisions about where the bottlenecks exist.
There is typically no silver bullet, but rather a combined solution between code and application delivery optimization that needs to take place. The insights can point to adjustments to database services, offloading third-party services to their containers, code improvements, and web app cloud design changes, among others.
CDN performance and security can usually be inspected first to see how much of the data in the request path can be optimized at the edge. For applications managed in AWS, recommended cloud improvements can be made, such as adjusting load balancing rules to better distribute incoming traffic across multiple web servers; utilizing auto-scaling tools to intelligently adjust the number of web servers based on incoming traffic; rightsizing Amazon Aurora services to improve database performance; offloading resource-intensive tasks to AWS Lambda; and storing certain static assets in Amazon S3 to reduce website load times.
At the same time, application development improvements can be made such as adjusting caching rules for frequently accessed data, optimizing code by removing unused code, minimizing HTTP requests and optimizing images, minifying CSS and JavaScript, enabling compression for website assets, as well as several other actions a development team can institute.
Regardless of what the prescription looks like, the objective of putting an Intelligent CloudOps practice in place is to continuously drive data out of your tech stack to influence decisions at every layer, rinse and repeat.
Webscale would love to help you get started on your Intelligent CloudOps journey. For a free, no-pressure conversation about your current tech stack, and an assessment of your storefront and where you could be losing money, reach out to us via the form at the bottom of the page.
Tune in to our final blog on this topic, where we look at how to turn TCO costs into true ROI for your business.






