



In an earlier article on perceptron algorithms, we looked at the concepts of weighted sums and thresholding. The output was passed through a threshold function, that blocked all the negative values from passing.
Activation functions
The disadvantage of using a unit step function is that it is not continuous. Therefore, weight updation will not be done efficiently. This led to several activation functions being introduced to ensure a better generalization of the models.
This tutorial will look at some of the activation functions used frequently and implement them from scratch. Since this is an article on activation functions, we will code each of them using Python Classes. We will make use of these classes in the upcoming articles.
What are activation functions?
The datasets that we work with are usually non-linear. The decision boundaries are also non-linear most of the time. A perceptron model without the threshold function is just a linear shift and scale operation performed on the inputs. To model the non-linear datasets, one needs to add a layer of nonlinearity.
Therefore activation functions introduce nonlinearity to better model the information. The universal approximation theorem states that if a neural network has more than 2 non-linear layers, it can model any input irrespective of its nonlinearity degree.
Why have so many activation functions?
The reason for introducing the various activation functions is to reduce the computational load and improve the computation of gradients during gradient computation. Back-propagation is the algorithm that introduced making small changes in the weights accordingly to minimize any errors.
This idea works well in theory, but computing the gradients and finding the global minimum is a computationally challenging task. There are many optimization techniques, such as gradient-based techniques, meta-heuristic optimization algorithms, etc. These activation functions are used with gradient descent optimization algorithms.
Activation functions
Let’s list some of the activation functions that we will be covering in this tutorial:
- Step activation function
- Sigmoid activation function
- Softmax activation function
- Hyperbolic tangent activation function
- Rectified linear unit (ReLU) activation function
- Leaky ReLU activation function
Step activation function
The step activation function, as discussed in the perceptron algorithm, is shown below. It is discontinuous, and therefore, the gradient computations are erroneous at points of discontinuity.
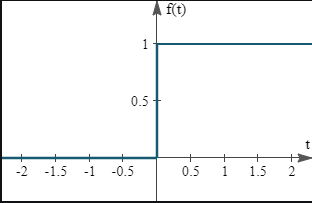
For a more in-depth discussion on the step function, refer to this previous article on perceptrons.
Sigmoid activation function
Step functions are not as informative as we would like them to be due to the discontinuity present at 0. During the training and optimizing of the networks, the step function gathers minimal information from the training data and therefore is of no use. The sigmoid function represents the same range and is a continuous variant of the step function.
It is given by the formula below:
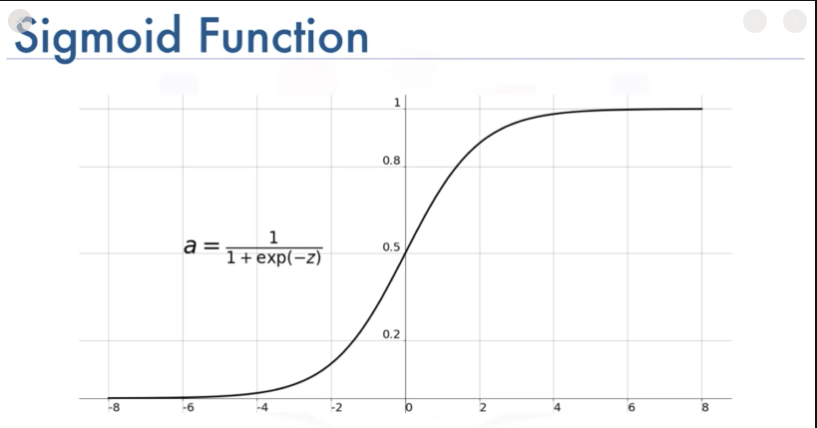
This function works very well with shallow neural network architectures. However, for deeper neural architectures, it is replaced with the Rectified Linear Unit activation function.
Code
import numpy as np
class Sigmoid():
def __call__(self, x):
return 1 / (1 + np.exp(-x))
Softmax activation function
Softmax is an activation function that stems from logistic regression. Logistic regression is a classification algorithm where the outputs are numbers. The class that outputs the largest number is denoted as the output class.
However, if two numbers are 400 and 500, can we confidently say that the class with the output of 500 is the target? There is a chance that 400 could also be the output.
To avoid such a confusion, softmax outputs the probability distribution of the class outputs. We can think of it as a squeeze function.
If the output is small, then it makes it as close to 0 as possible. On the other hand, if the output is relatively large, it increases the output probability to the neighborhood of 1.
Mathematically this is written as:
Code
import numpy as np
class Softmax():
def __call__(self, x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / np.sum(e_x, axis=-1, keepdims=True)
Hyperbolic tangent activation function
This is similar to the sigmoid activation function, except for the range of output values. The range of the sigmoid output is [0,1][0,1]. The range of the tanH function is [−1,1][−1,1]. The distinction between tanH and sigmoid is visible in the image shown below.
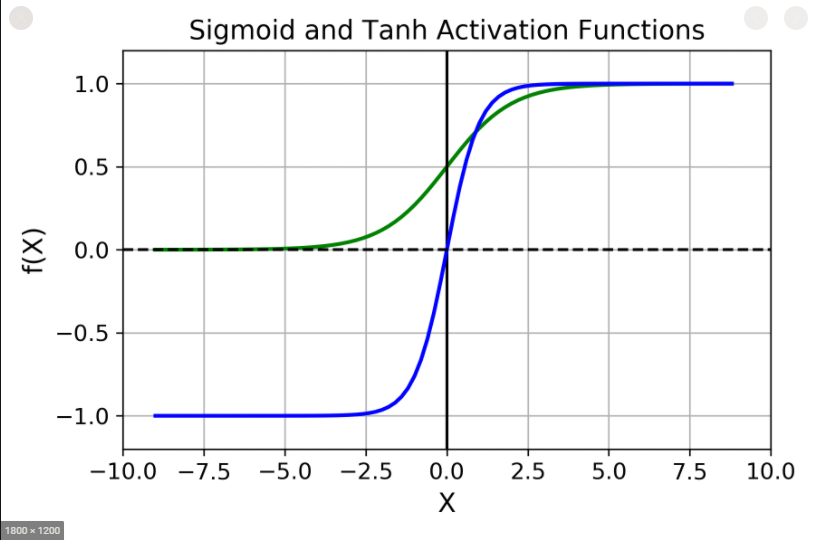
Mathematically, it is given by the following equation:
For more information on the mathematical formula to represent tanH, visit the following link.
Code
import numpy as np
class TanH():
def __call__(self, x):
return 2 / (1 + np.exp(-2*x)) - 1
Rectified linear unit activation function
ReLU is one of the most widely used activation functions today. Overall it allows positive values to pass through and stops negative values.
It’s linear in the domain (0,∞](0,∞].
The first question that one must ask is how a non-continuous linear function will introduce nonlinearity? ReLU, when used individually, does not introduce non-linearity. But, when more than a couple of non-linear layers of ReLU are used, nonlinearity does set in.
A more detailed explanation for the working of ReLU is given at this link.
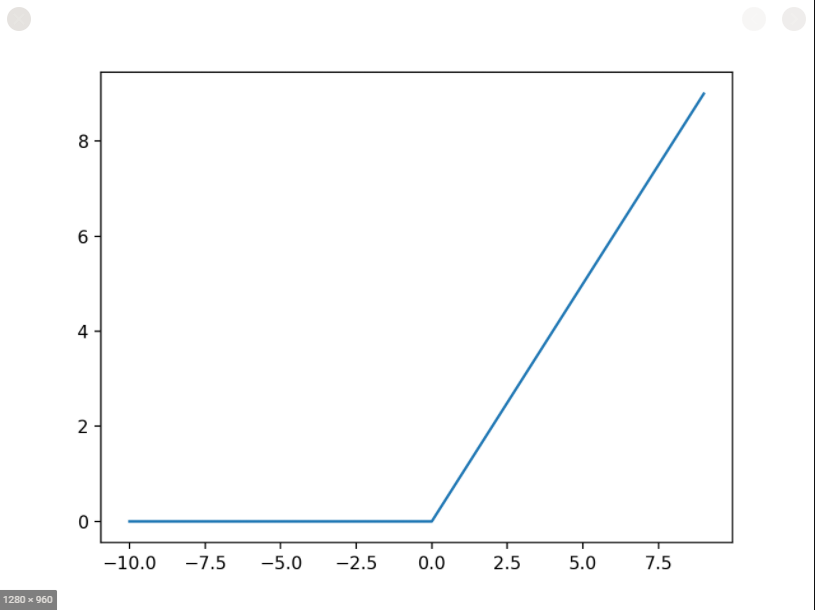
Mathematically, it is given by the following equation:
Code
import numpy as np
class ReLU():
def __call__(self, x):
return np.where(x >= 0, x, 0)
Leaky Rectified linear unit activation function
Leaky ReLU is a modification of the Rectified Linear Unit. In ReLU, there is an absolute cutoff present at 0. Any value less than zero is discarded. In leaky ReLU, the positive values are passed through.
The negative values are multiplied by a constant between 0 and 1 and then passed through. This way, only a fraction of the negative values are passed through, thus striking a balance between gradient computations and information loss.
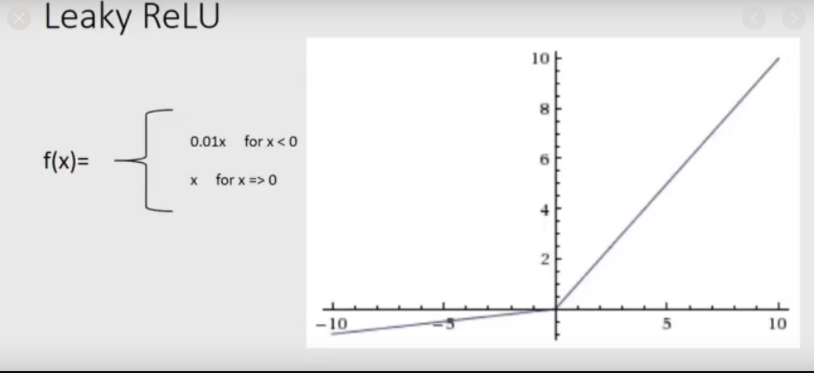
Code
import numpy as np
class LeakyReLU():
def __init__(self, alpha=0.2):
self.alpha = alpha
def __call__(self, x):
return np.where(x >= 0, x, self.alpha * x)
Conclusion
In this article, we have looked at some frequently used activation functions. We also looked at how we write the functions mathematically. We should use the code given as a blueprint for these activation functions. We will make use of these blueprints in the upcoming articles to come.




Comments: