



Apriori algorithm is a machine learning model used in Association Rule Learning to identify frequent itemsets from a dataset. This model has been highly applied on transactions datasets by large retailers to determine items that customers frequently buy together with high probability.
Using its knowledge, retailers can structure deals on their products, such as offering a discount on best rules or attaching a free item depending on the quantity of best-associated rules customers buy together. Whichever the case, customers end up spending extra more to benefit from these deals. As a result, the business experience not only high sales but also a high profit.
In this article, we shall learn the intuition behind the apriori algorithm and later implement it in python.
How does apriori algorithm work?
The Apriori algorithm uses three matrices to find the best association rules from a dataset, making its approach on datasets successful. These matrices include:
- Support: It measures the number of times a particular item or combination of items occur in a dataset. The mathematical formula for support is;
$$Support(I) = \frac{transaction containing(I)}{total.transactions}$$where $$I$$ is a particular item in an items dataset. - Confidence: It measures how the consumer is likely to consume $$I_2$$ given they have consumed $$I_1$$. It’s calculated using the formula:
$$Confidence(I_1\rightarrow I_2) = \frac{transaction cointaing(I_1and I_2)}{transactions containing(I_1)}$$ - Lift: A lift is a metric that determines the strength of association between the best rules. It is obtained by taking confidence and diving it with support. Its mathematical formula is as follows:
$$Lift(I_1\rightarrow I_2) = \frac{Confidence(I_1\rightarrow I_2)}{Support(I_2)}$$
Since we now understand the basics of the apriori algorithm, let us learn how to develop this model in python to use it and obtain the best association rule from a dataset.
Implementing the Apriori algorithm
Our implementation will use a customer’s transactions dataset containing records of customers’ transactions with a particular business within a specific week. Our objective is to learn the best association rule from this dataset and return this rule to the business owner.
Using this rule, the business owner can now offer some deals to the customers, which will increase sales and profit. We can download this dataset here.
Step 1: Data preprocessing
This step involves importing the libraries and later transforming our data into a suitable format for training our apriori model. Therefore, the first thing we shall do in this package is to install an apyori package containing all the apriori model algorithms.
- Installing the required package
# installing the apyori package
!pip install apyori
- Importing the libraries Below is the code that imports the required libraries we are going to interact with within this session.
# importing libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- Importing the dataset
Our dataset contains no column names. Therefore, in the importing stage, we need to specify this using the header argument; otherwise, python will treat the first observation as column names, which should not be the case. Below is the code that imports our dataset as a pandas data frame.
Data = pd.read_csv('/content/drive/MyDrive/Market_Basket_Optimisation.csv', header = None)
- Transforming our pandas dataset into a list dataset
Since we shall be training an apriori model, which takes inputs in a list format, we need to transform our pandas’ data frame into a list of transactions. To create this list, we start by initializing an empty list. We then populate this with different transactions in our pandas’ data frame.
To achieve this, we shall use a for-loop function that will iterate over the different observations of our pandas dataset and populate our empty list with the elements of such observations.
We then take the append function from our created list, which will add different elements from our dataset into our list one by one.
However, to succeed in this step, we shall use two for-loops, one to iterate over all the 7501 different transactions and the second one overall the 20 columns, so that the append function adds each element to the list independently.
The following code transforms our dataset into a list of transactions.
# Intializing the list
transacts = []
# populating a list of transactions
for i in range(0, 7501):
transacts.append([str(Data.values[i,j]) for j in range(0, 20)])
To this point, the data preprocessing stage for our apriori model is complete. Next, we implement the model itself now.
Step 2: Training apriori model
Below is the code that trains our apriori model.
from apyori import apriori
rule = apriori(transactions = transacts, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2, max_length = 2)
Step 3: Visualising the results
If we call the list output of the above code, we obtain a non-tabular result, challenging to interpret.
Therefore, to make things easier, we shall transform the outputs into a pandas data frame. The code below carries out this task.
output = list(rule) # returns a non-tabular output
# putting output into a pandas dataframe
def inspect(output):
lhs = [tuple(result[2][0][0])[0] for result in output]
rhs = [tuple(result[2][0][1])[0] for result in output]
support = [result[1] for result in output]
confidence = [result[2][0][2] for result in output]
lift = [result[2][0][3] for result in output]
return list(zip(lhs, rhs, support, confidence, lift))
output_DataFrame = pd.DataFrame(inspect(results), columns = ['Left_Hand_Side', 'Right_Hand_Side', 'Support', 'Confidence', 'Lift'])
Displaying the results non-sorted
output_DataFrame
Output:
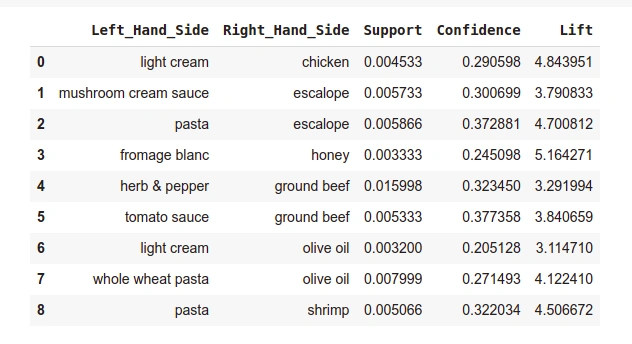
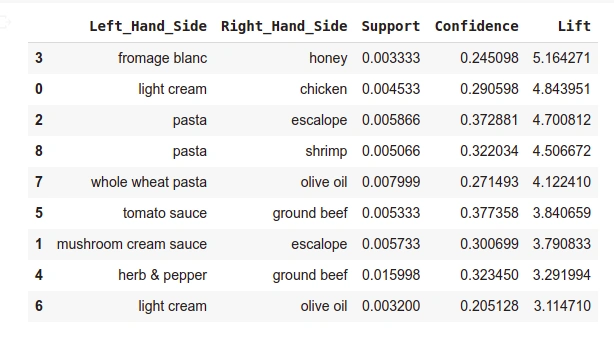
Displaying the results sorted by descending order of Lift column
output_DataFrame.nlargest(n = 10, columns = 'Lift')
Output:
Conclusion
This article looked at the general intuition behind the apriori algorithm and showed how we could implement this algorithm in python using a transactional dataset.




Comments: