



By their very nature machine learning models are data-hungry. They require a lot of data to make decisions. However, always having high quality labeled data available to train models is often a costly (and tedious) task. Active learning can serve as an answer to this. This approach can reduce the training data needed to train a model.
Contents
- Introduction to active learning.
- Steps to use active learning on unlabelled data.
- Three active learning frameworks.
- Query strategies.
Prerequisites
This article requires an understanding of supervised learning and machine learning in general. This article may be of help with the mentioned prerequisites.
Active learning
In supervised learning, a great amount of labeled data is needed for training. However, we might encounter a situation where we have a large pool of unlabelled data. To apply a supervised algorithm on such data, we would need to label every instance. However, this would be a tedious, time-consuming, and an expensive process.
However, a semi-supervised approach would allow us to label a few data examples to train a model and still achieve great precision. This is active learning.
Active learning describes an approach where data that needs to be labeled to train a model is prioritized. Specifically, the data that is prioritized has the highest impact on the performance of a model. Prioritizing informative data allows one to train a model on priority data instead of training it on the whole dataset.
We describe this approach as semi-supervised. Unsupervised learning approaches consider unlabelled data while supervised ones prefer a fully labeled dataset. Active learning does not need a fully labeled set.
Active learning involves the use of an oracle. In this context, an oracle is the information source. That is an entity that is capable of labeling data examples when the learner cannot. This is often a human expert.
To further understand this type of learning, let’s look at the process of carrying out active learning on an unlabelled dataset.
Steps
To use active learning on an unlabelled dataset, there are several common steps to consider:
- First, a tiny portion of the training data needs to be manually labeled.
- The model would then need to be trained on this portion of labeled data. The point of doing this is not to achieve the best performance but rather an insight. This allows analysis of sections of the parameter space to be prioritized to further improve the model.
- After training is completed, the learner is then tasked to predict each of the unlabelled examples’ class.
- Unlabelled datapoints are scored in terms of their informativeness. We shall discuss how this informativeness is evaluated later on.
- This process may be repeated once the best strategy to carry out labeling has been selected. A new labeled dataset may be used to train a new model. A query strategy may be used to determine the approach to label this new set. We shall explore these strategies later. The iteration allows one to optimize the labeling approach, as the models improve with each iteration.
Active learning frameworks
There exist three main frameworks of active learning. Let’s introduce them below.
1. Stream-based selective sampling
This is an active learning technique where training examples are sent to an algorithm in a stream. The algorithm receives individual training examples for consideration. The informative value of each training example is evaluated.
The algorithm then immediately decides whether to label a given example or query the oracle to label the example. Let’s look at the image below to intuitively understand this technique.
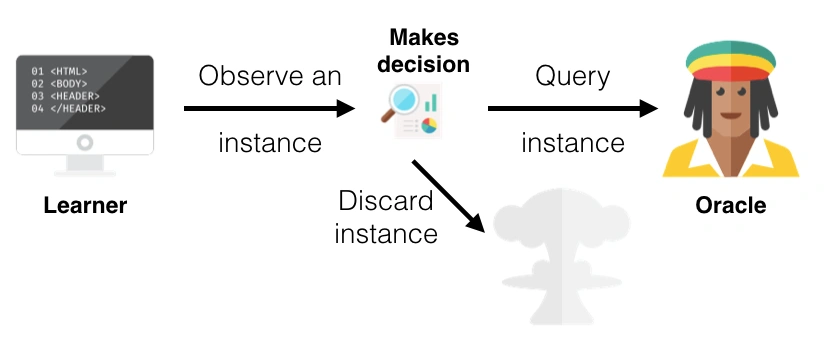
Stream-Based Sampling
From the image, we can see that the learner first observes an example, then decides whether to query the oracle or discard the example.
As mentioned above, the decision to select an example can be determined by the example’s informativeness. To determine the informative value of an example, one can use a query strategy. We shall discuss this more later on.
2. Pool-based sampling
For numerous real-world machine learning problems, we can collect large collections of unlabelled data at once. This is a motivating factor behind pool-based sampling. It assumes that there is a sizeable pool of unlabelled data.
Pool-based sampling tries to evaluate an entire dataset before choosing the best set of examples. This process involves identifying the informativeness of all the provided examples, then selecting a given number of examples to train a model.
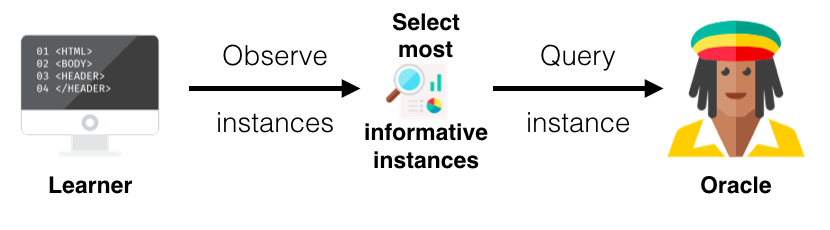
Pool-Based Sampling
The image shows that the learner observes examples and selects the most informative ones.
While stream-based sampling goes through data sequentially, pool-based sampling evaluates the entire set then ranks the examples. Stream-based technique makes query decisions in an individual sense, that is, considering a single example at a time. The pool-based method selects the best queries after ranking. This is the difference between pool-based and stream-based sampling.
3. Membership query synthesis
In this approach, the learner can create examples for labeling. These examples are based on the training examples to maximize the effectiveness of learning.
For instance, the data may be images of letters. The learning agent may generate an image akin to a single letter. The generated image may be oriented differently, such as being rotated by a certain degree. Or a portion of the letter may be left out. This is then sent to the oracle for labeling.
The image below represents this process.
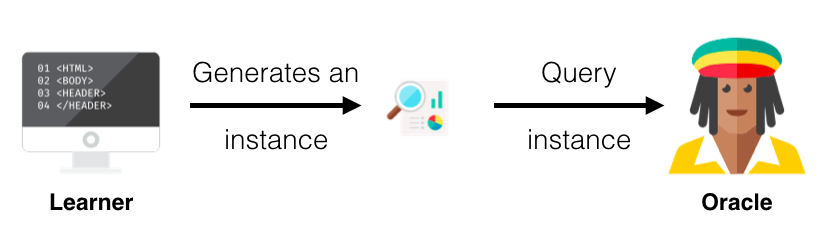
Membership Query Synthesis
However, since this approach involves the generation of examples, it may prove to be awkward for a human annotator as the oracle. Consider a scenario where the learner attempts to classify handwritten characters.
The learner may generate images of artificial symbols that cannot be recognized. It can generate symbols with no semantic meaning. For natural language processing tasks, it may generate segments of text that are no more useful than gibberish.
Query strategies
The three techniques covered in the previous section evaluate the informativeness of unlabelled examples. This evaluation is through the use of query strategies. We will explore a few query strategies in the following section.
Least confidence
Simply put, the learner picks an example for which it has the least confidence in and chooses the most likely label to be assigned to it (by asking the oracle if needed). Let’s use an example to understand this strategy better.
Let’s have instances C1 and C2. Each of these instances has probability values across three labels. C1 has a probability of 0.8, 0.17, and 0.03 across labels 1, 2, and 3. C2 has 0.25, 0.45 and 0.3 across labels 1, 2 and 3.
C1 has a probability of 0.8 for Label 1. This means that the learner is confident that C1 should be labeled 1. This is in comparison with 2 and 3, with probabilities of 0.17 and 0.03, respectively.
When it comes to C2, the learner is less sure about its label. The probabilities are 0.25, 0.45, and 0.3. The probabilities are closer to each other compared to the case of C1.
The learner cannot for certain determine the correct label for C2. The learner would think that C2 should be labeled 2, but a probability of 0.45 does not demonstrate confidence.
Since querying is a process used to retrieve information, the learning agent would choose C2 to query the oracle for its true label using the least confidence method. The learner would ask the oracle to provide the correct label since it lacks the confidence to do it itself. This is due to the low probability value assigned to C2.
Margin sampling
Least confidence considers the most likely label while disregarding the probabilities of other labels. This is a downside of the least confidence strategy.
Margin sampling attempts to improve upon this shortcoming. It does this by choosing the example with the tiniest difference between the most and second most probable labels.
Let’s use our previous example to show this.
Once more, C1 has a probability of 0.8, 0.17, and 0.03 across labels 1, 2, and 3. C2 has 0.25, 0.45 and 0.3 across labels 1, 2 and 3. Considering C1, the most probable label is 1, with a probability of 0.8.
The second most probable label is 2, with a probability of 0.17. The difference between the two probabilities (0.8 -0.17) gives us 0.63. As for C2, we get 0.45 – 0.3, which is 0.15.
As per the results of getting the differences, C2 will be chosen for the querying of its label.
Entropy sampling
Entropy refers to the quantity of uncertainty of a random variable. It’s possible to calculate the entropy of the predicted label probabilities.
If the probability distribution of the examples is uniform, the level of uncertainty is higher. Higher levels of entropy show that there is great uncertainty in the probability distribution.
In each step of active learning, the learner calculates entropy using the predicted label probabilities. This is done for every unlabelled example in the training data.
The learner then chooses the example with the greatest entropy. Such an example is one in which the learner is the least certain about which class it belongs to.
To learn more about entropy, here’s a short post about Shannon Entropy that explains the theory and calculation of entropy.
Closing
Active learning allows us to use large unlabelled datasets while avoiding the prospect of having to label every single instance in the set. This reduces the tedium associated with data labeling. A lot of time, effort, as well as financial resources, are saved through this approach.
We have gone through an introduction to active learning and some techniques used with it. I hope that the concepts we have covered will help you with your machine learning journey.
Happy reading!
References and Further Reading
- Active Learning Literature Survey
- What is Active Learning?
- Active Learning in Machine Learning
- Introduction to Active Learning
- Accelerate Machine Learning with Active Learning
- Active Learning Tutorial
- Active Learning: Curious AI Algorithms
- Active Learning as a Way of Increasing Accuracy
- Entropy: How Decision Trees Make Decisions
- Active Learning Sampling Strategies
- Active Learning as a Way of Increasing Accuracy




Comments: