





GraphQL is a widely adopted alternative to REST APIs because of the many benefits that it offers, including performance, efficiency, and predictability. While the advantages are significant, many developers become frustrated with latency challenges when implementing GraphQL. One solution to this is deploying the application across a distributed system. Let’s dive into these challenges and discuss some solutions that can be implemented today.
TLDR?
Get started for free or jump straight into tutorials for deploying distributed GraphQL on Webscale CloudFlow:
- Hasura
- Hasura with AWS RDS and Aurora Postgres
- Hasura and Supabase
- Postgraphile and Supabase
- GraphQL with Apollo Router
- GraphQL with Apollo Server
- Contact us to let us know what you need or get started now.
Why GraphQL?
GraphQL was built by Facebook in 2012 to combat issues with their mobile application. It was having to fetch so much data via their existing API that it was bogging down the user experience. They ended up completely rebuilding that model. Their challenge: the need to make the Facebook app scalable within a mobile application that was limited in resources. They asked, why does my app need all this information from my REST API. Why do I have to make multiple API calls to get that information? And, ultimately, why can’t there be just one call that returns all the information needed, and only that information? Hence, the creation of GraphQL.
How Does GraphQL Work?
GraphQL deliberately moved away from the twenty-year-old REST API model, with the Facebook team saying, instead we want to fetch content with just one HTTP request and we want it to return only the information that we need. GraphQL’s tag line is “Ask for what you need, get exactly that”, aiming to make it easier to evolve APIs over time, and enable more powerful developer tools. The query language is designed to replace schema stitching and solve challenges associated with REST APIs, including separation of codes, brittle gateway code and coordination.
Since it was open sourced in 2015, GraphQL has become highly popular because of the flexibility and efficiencies it offers. Last year, The Linux Foundation set up the GraphQL Foundation to build a vendor-neutral community around it.
Caching Challenges with GraphQL
However, there are various challenges with GraphQL, particularly when trying to connect data across a distributed architecture. One of the main difficulties involves caching, which CDNs are unable to solve natively without altering their architecture.
With GraphQL, since you are using just one HTTP request, you need a structure to say, “I need this information”, hence you need to send a body. However, you don’t typically send bodies from the client to the server with GET requests, but rather with POST requests, which are historically the only ones used for authentication. This means you can’t analyze the bodies using a caching solution, such as Varnish Cache, because typically these reverse proxies cannot analyze POST bodies.
This problem has led to comments like “GraphQL breaks caching” or “GraphQL is not cacheable”. While it is more nuanced than this, GraphQL presents three main caching issues:
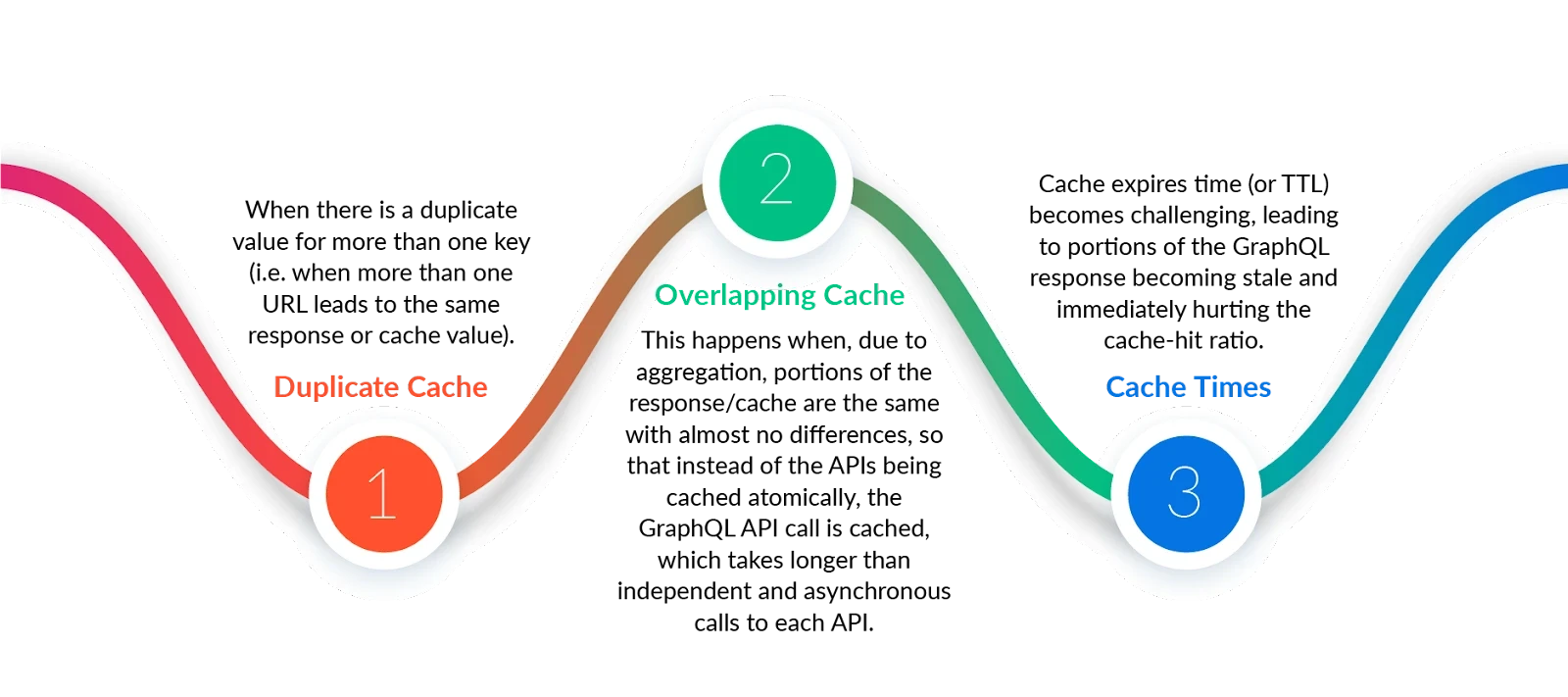
- Duplicate Cache – When there is a duplicate value for more than one key (i.e. when more than one URL leads to the same response or cache value).
- Overlapping Cache – This happens when, due to aggregation, portions of the response/cache are the same with almost no differences, so that instead of the APIs being cached atomically, the GraphQL API call is cached, which takes longer than independent and asynchronous calls to each API.
- Cache Times – Cache expires time (or TTL) becomes challenging, leading to portions of the GraphQL response becoming stale and immediately hurting the cache-hit ratio.
Some CDNs have created a workaround of changing POST requests to GET requests, which populates the entire URL path with the POST body of the GraphQL request, which then gets normalized. However, this insufficient solution means you can only cache full responses. For the best performance, we want to be able to only cache certain aspects of the response and then stitch them together. Furthermore, terminating SSL and unwrapping the body to normalize it can also introduce security vulnerabilities and operational overhead.
The next challenge is that you need to have both a client application and a server to be able to handle GraphQL requests. There are some great out-of-the-box solutions out there, including Apollo GraphQL, which is an open source framework around the GraphQL client and server. While the GraphQL server is easy to implement at the origin, it becomes significantly more complex when trying to leverage performance benefits in a distributed architecture.
What Solutions Are Available?
GraphQL becomes more performant by storing and serving requests closer to the end user. It is also the only way to minimize the number of API requests. This way, you can deliver a cached result much more quickly than doing a full roundtrip to the origin. You also save on server load as the query doesn’t actually hit your API. If your application doesn’t have a great deal of frequently-changing or private data, it may not be necessary to utilize edge caching, but for applications with high volumes of public data that are constantly updating, such as publishing or media, it’s essential.
Distributed GraphQL on Webscale CloudFlow’s Edge Compute Platform
Webscale’s Edge Compute Platform, CloudFlow, offers a platform to build a distributed GraphQL solution that is fully configurable to address caching challenges without having to maintain a distributed system. We give developers full flexibility and control to distribute GraphQL servers, such as Apollo, to get the benefits of stitched GraphQL bodies, along with an optimized edge network and the opportunity to configure caching layers to meet performance and scalability requirements.
Here’s an example of what an edge node might look like:
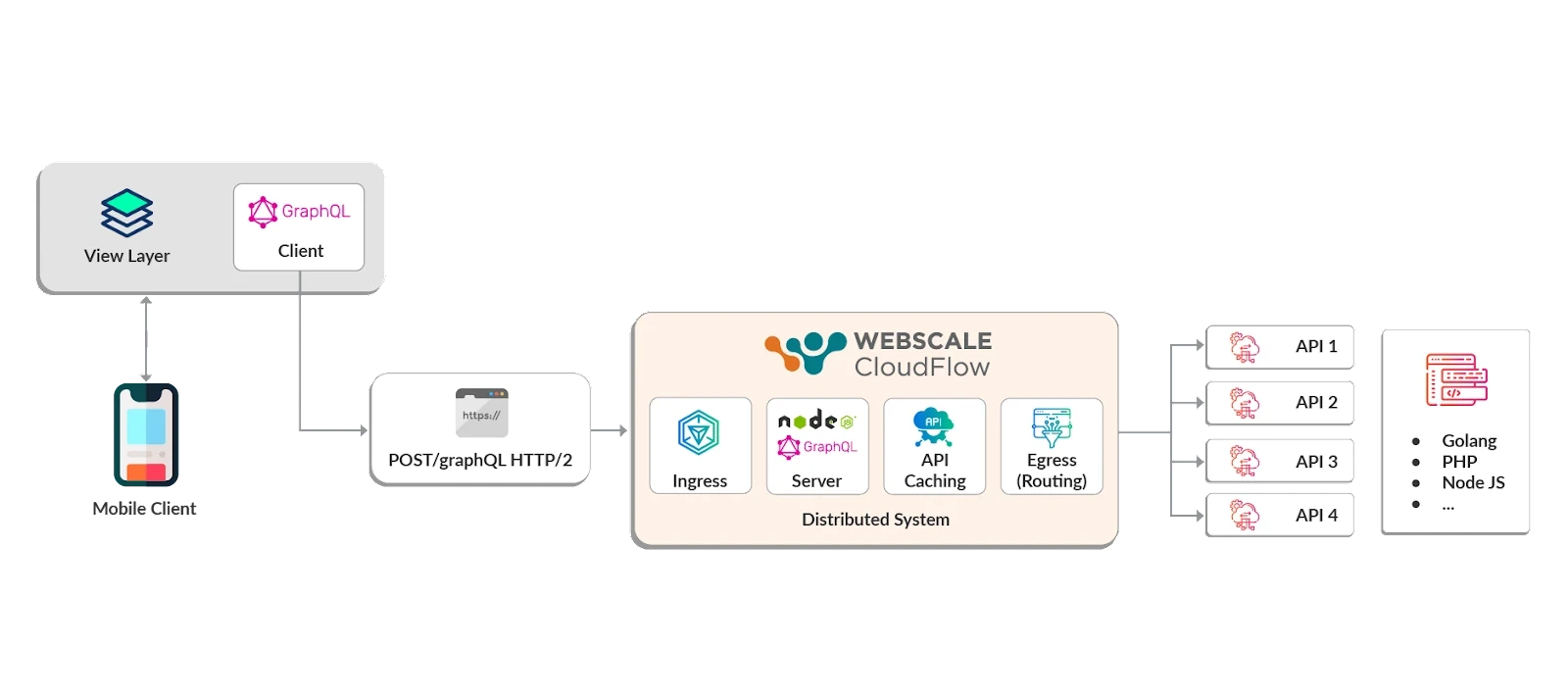
Let’s say you decide to use a JavaScript-based GraphQL server, such as Apollo. You can easily drop it into CloudFlow Node JS edge module and add a caching layer behind it. There are significant benefits to utilizing Varnish Cache (or other caching solution) behind GraphQL servers to cache API requests, particularly when it comes to reducing load time and increasing the time to deliver.
With CloudFlow, you have the further benefit of managing your entire edge stack in a single solution.
Apollo Federation
Apollo Federation is another solution to provide an open source architecture for building a distributed graph. Or, in other words, it offers the opportunity to implement GraphQL in a microservices architecture. Their goal: “Ideally, we want to expose one graph for all of our organization’s data without experiencing the pitfalls of a monolith. What if we could have the best of both worlds: a complete schema to connect all of our data with a distributed architecture so teams can own their portion of the graph?”
While the Apollo Federation solution helps address scalability challenges, developers are still faced with the same caching challenges. Because of its flexibility, the CloudFlow platform can also provide a platform for distribution of the Apollo Federation solution, so that developers can add and configure caching layers to improve performance and efficiency.
Do you have specific GraphQL challenges you’d like to discuss? Chat with a Webscale Engineer







