





Organizations are seeking to migrate more application logic to the edge for performance, security and cost-efficiency improvements. Edge migration poses numerous challenges for developers compared to cloud deployments:
Typical cloud deployments involve a simple calculation of determining which single cloud location will deliver the best performance to the maximum number of users, then connecting your code base/repository and automating build and deployment through CI/CD. But what happens when you add hundreds of edge endpoints to the mix, with different microservices being served from different edge locations at different times? How do you decide which edge endpoints your code should be running on at any given time? More importantly, how do you manage the constant orchestration across these nodes among a heterogeneous makeup of infrastructure from a host of different providers?
It’s worth diving deeper into this topic from a developer perspective with some insights taken from our recent white paper on Solving the Edge Puzzle. The question is relatively straightforward: is it possible to continue developing and deploying an application in the same (or similar) fashion as with the cloud or centralized hosting, yet still have users enjoy all the benefits of the edge? The development challenge can be distilled down into three areas: code portability, application lifecycle management and familiar tooling as it relates to the edge.
Code Portability
Why do we need code portability? As discussed above, an ideal state allows for similar development/deployment across various ecosystems. Workloads at the edge can vary across organizations and applications. Examples include:
- Micro APIs – hosting small, targeted APIs at the edge, such as search or full-featured content exploration with GraphQL, to enable faster query response while lowering costs.
- Headless applications – decoupling the presentation layer from the back end to create custom experiences, increase performance or improve operational efficiency.
- Full application hosting – rather than beaconing back to a centralized origin, databases are hosted alongside applications at the edge, and then synced across distributed endpoints.
This can almost be viewed as a hierarchy or progression in edge computing, as the inevitable trend for application workloads is moving more of the actual computing as close to the user as possible. But as developers adopt edge computing for modern applications, edge platforms and infrastructure will need to support and facilitate portability of different runtime environments.
It’s important to recognize that while private vs public cloud vs edge may seem like architectural decisions, these are not mutually exclusive. Centralized computing could be reserved for storage or compute-intensive workloads, for example, while edge is used to exploit data or promote performance at the source. Seen through a developer lens, this means application runtimes must be portable across the edge-cloud continuum.
How do we get there? Containerization is the key to enabling portability, but it still requires careful planning and decision making to achieve. After all, portability and compatibility are not the same thing; portability is a business problem, while compatibility is a technical problem. Consider widely used runtime environments, such as:
- Node.js, used by many businesses, large and small, to create applications that execute JavaScript code outside a web browser;
- Java Runtime Environment, a prerequisite for running Java programs;
- .NET Framework which is required for Windows .NET applications; and
- Cygwin, a runtime environment for Linux applications that allows them to run on Windows, macOS, and other operating systems.
Developers need to be able to run applications in dedicated runtime environments with their programming language of choice; they can’t be expected to refactor the code base to fit into a rigid, pre-defined framework dictated by an infrastructure provider. Moreover, the issues of portability, compatibility and interoperability don’t just apply to private vs public cloud vs edge, they are also important considerations across the edge continuum as developers adopt global, federated networks featuring multiple vendors to improve application availability, operational efficiency and avoid vendor lock-in. Simply stated, multi-cloud and edge platforms must support containerized code portability, while offering the flexibility required to adapt to different architectures, frameworks and programming languages.
Application Lifecycle Management
In addition to code portability, another edge challenge for developers is easily managing their application lifecycle systems and processes. In the DevOps lifecycle, developers are typically focused on the plan/code/build/test portion of the process (the areas in blue in the image below). With a single developer or small team overseeing a small, centrally managed code base, this is fairly straightforward. However, when an application is broken up into hundreds of microservices that are managed across teams, the complexity grows. Add in a diverse makeup of deployment models within the application architecture, and lifecycle management becomes exponentially more complex, impacting the speed of development cycles.
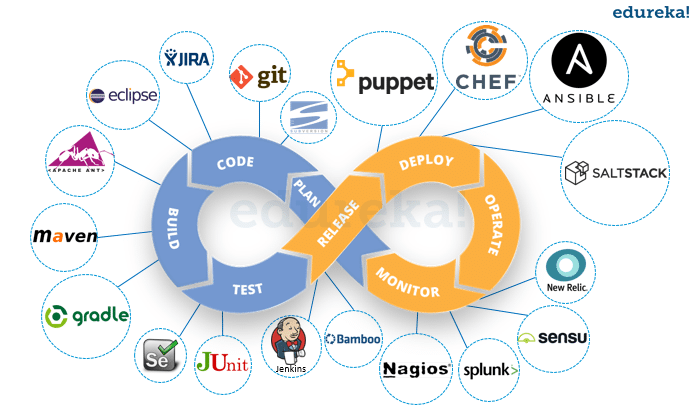
Image source: edureka
In fact, the additional complexities of pushing code to a distributed edge – and maintaining code application cohesion across that distributed application delivery plane at all times – are often the primary factor holding teams back from accelerated edge adoption. Many teams and organizations are turning to management solutions such as GitOps and CI/CD workflows for their containerized environments, and when it comes to distributed edge deployments these approaches are usually a requirement to avoid increased team overhead.
Familiar Tooling
Which brings us to the third challenge for edge deployment: tooling. If developers plan for code portability and application lifecycle management, but are forced to adopt entirely different tools and processes for edge deployment, it creates a significant barrier. As the theme of this post makes clear, efficient edge deployment requires that the overall process – including tooling – is the same as or similar to cloud or centralized on-prem deployments.
GitOps, a way of implementing Continuous Deployment for cloud native applications, helps us get there. It focuses on a developer-centric experience when operating infrastructure, using tools developers are already familiar with including Git and Continuous Deployment tools. These GitOps/CI/CD toolsets offer critical support as developers move more services to the edge, improving application management, integration and deployment consistency.
Beyond more general cloud native tooling, as Kubernetes adoption continues to grow, Kubernetes-native tooling is becoming a stronger requirement for application developers. Kubernetes native technologies generally work with Kubernetes’s CLI (‘kubectl’), can be installed on the cluster with the Kubernetes’s popular package manager Helm, and they can be seamlessly integrated with Kubernetes features such as RBAC, Service accounts, Audit logs, etc.
Edge as a Service: Consistency is Key
As covered in our whitepaper, the key to accelerating edge computing adoption is making the experience of programming at the edge as familiar as possible to developers, explicitly drawing on concepts from cloud deployment to do so. But the added complexities that a distributed edge deployment brings introduces new challenges to achieving consistency across these experiences.
That’s why we offer an Edge as a Service(EaaS) platform, allowing developers to leverage code portability and use simple, familiar lifecycle management processes and tools at the distributed edge. The Webscale CloudFlow EaaS platform offers GitOps-based workflows, Kubernetes-native tooling, CI/CD pipeline integration, RESTful API, automated SSL/TLS integration and a complete edge observability suite. This, combined with the other benefits of EaaS for application deployment, gives developers the cost and performance benefits they’re looking for in an edge platform, without the need to master distributed network management.







