





“Optimization happens constantly, automatically, and transparently to the operations teams and the end users.”
Traditionally we have hosted applications in centralized locations. (Cloud hosting being the more recent incarnation of that hosting structure). Some of us have run “hub and spoke” models with the spokes fostered by legacy CDNs. This model means we have “always on” centralized hosting for the whole application and only some parts of the applications running in distributed locations on CDNs. Ultimately, we have been limited to run on a distributed footprint only those parts of an application that have not resulted in overly burdensome operational overheads for our Development and Ops teams to deploy and manage.
Why Not Decentralize the Whole App?
What if we can move to a decentralized hosting model rather than the hub and spoke of cloud + CDN?
What are the implications for;
- The end-user experience of the application
- Application deployment and operations overhead
- The cost of hosting
We would expect application distribution to result in one major positive and two serious negatives;
- Better performance experience for end users
- Significantly more complex Operations
- How can you deploy the application to many locations
- How can you choose and manage many locations
- The cost of hosting to increase significantly
- Your application would be always running in every distributed location all the time.
Conducting a CloudFlow Case Study
The following study was conducted to analyze these three aspects when running a distributed microservice application on the CloudFlow platform.
TL;DR
With CloudFlow, application distribution means;
- Significantly better user experience for end users everywhere
- No change to operations flows – it feels like working with a centralized application
- Cost Optimization – AI/ML driven automation to run only where and when users need the application
Deploying a Microservices Application
We deployed a microservices application consisting of an Nginx Server and a Fluent D data collector sending logs from the application to an external logging repository (in this case we followed CloudFlow’s New Relic integration steps). Both of these were deployed in Docker containers.
For K8s folks: When deployed to CloudFlow, they appear in the K8s dashboard Webscale provides as follows:
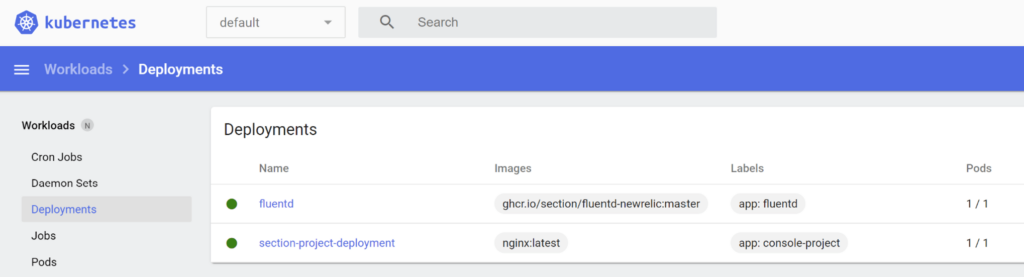
The experience of deploying an application to CloudFlow is exactly as though deploying to a single cloud location (or for K8s users, like deploying to a single K8s cluster).
- There is no operational burden to deploy to CloudFlow’s multi-location global platform.
- Use existing workflows including Kubernetes workflows
- The development teams and dev environment can stay exactly the same.
- The operations team can continue to collect and analyze logs from existing centralized locations
Webscale’s platform automatically took care of providing the following in the few minutes of set up;
- A URL – https://weathered-sun-8105.section.app/
- DNS set up
- SSL certs for the domain (Let’s Encrypt)
- DDoS Protection
Traffic and Measurement
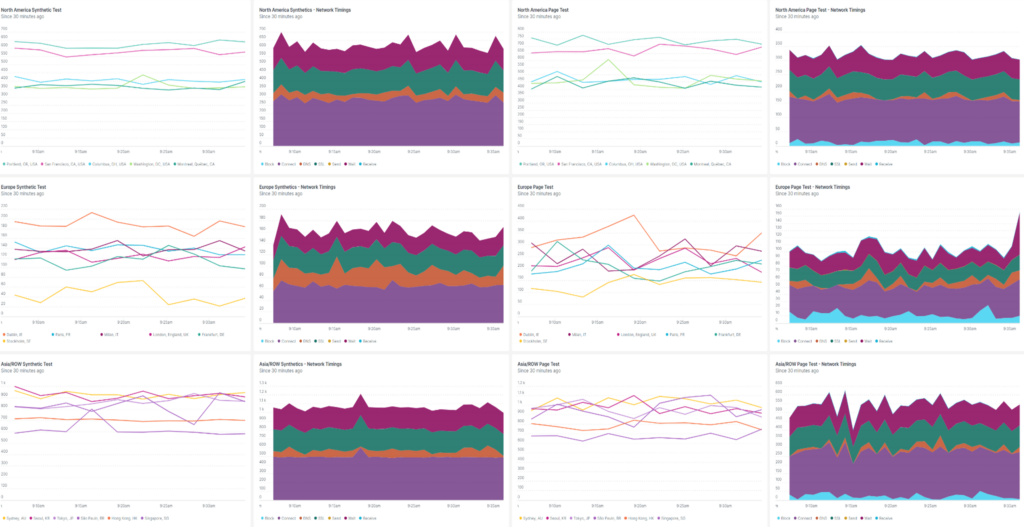
We used New Relic’s synthetic monitoring to generate traffic from all parts of the world and to measure the performance of the application for users in those parts of the world.
We set up three traffic groups firing both ping and full-page tests every minute.
- North America – on the top row of our dashboard
- Europe – middle row
- Asia and ROW – bottom row
Here is the traffic monitoring dashboard:
Testing the Application Centrally Deployed
The status quo for deploying an application would be to choose a hosting location based on an arbitrary or best guess as to where the ideal hosting location may be for your end users. Say, for example, you choose either the West or East of the USA for your application as a Cloud hosting location.
To test the status quo we used a static location selection policy to deploy the microservices application to just one US East location. In this case, New York.
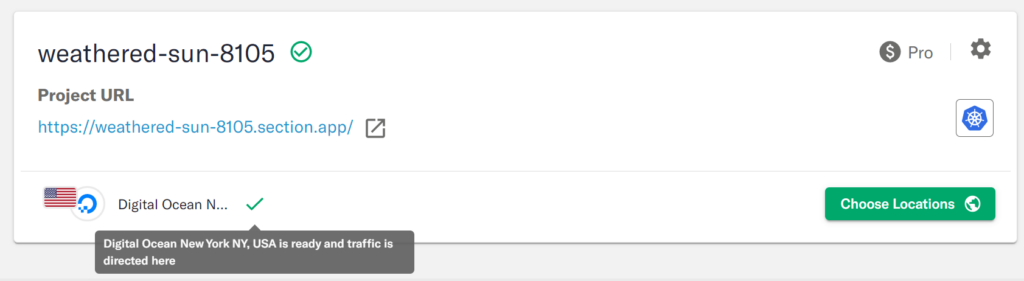
Transparently to Ops teams and end users, in just a few minutes, CloudFlow takes care of;
- Resetting networking (DNS, Anycast) to route traffic to this location
- Deploying the Nginx container in this location and starts serving traffic from it when ready
- Deploying the Fluent D container in this location (which starts sending logs to New Relic when ready)
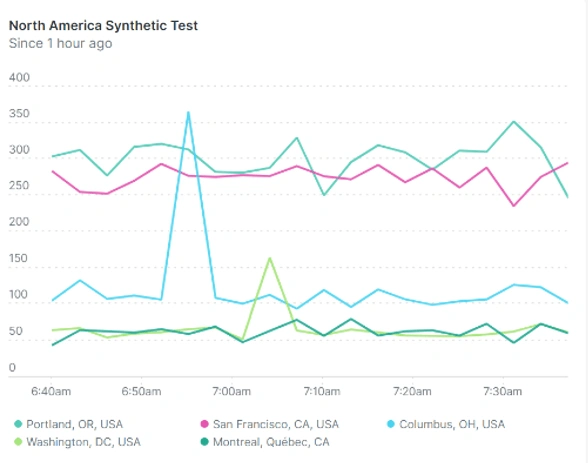
At this point we can see from the following North American centric view that Washington, Columbus, and Montreal all perform reasonably well but the Western locations are having a sub-par experience.
This is what you would expect from a simple, single location application deployment strategy. All locations not in the locale of the chosen hosting center must suffer.
Distributing the Application to Chosen Locations
What if we can deploy the application closer to those users in the Western parts of the USA?
By making a few simple tweaks to the platform’s location selector, we can ask CloudFlow to deploy this microservice application to six specific locations across North America.
Note that at this point we have CloudFlow’s Automatic Optimization turned off and we are making a “Static” or always-on policy selection whereby we are choosing the locations in which the application will be always deployed.
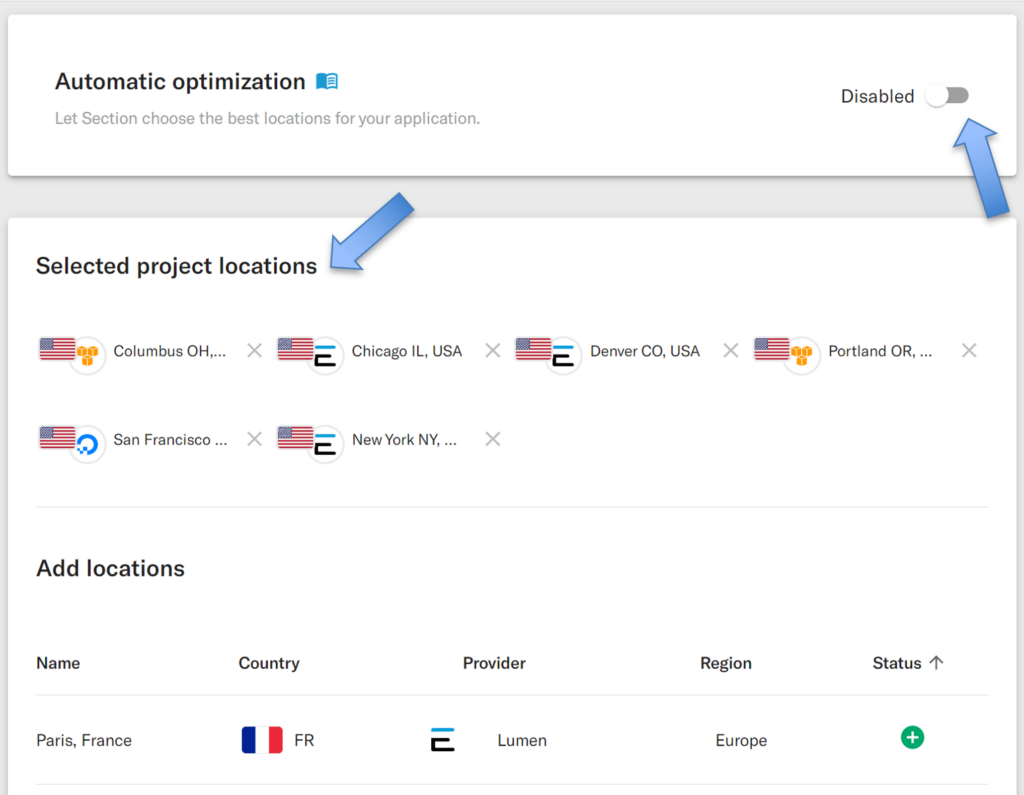
This resulted in the deployment pattern as follows in about 10 minutes:
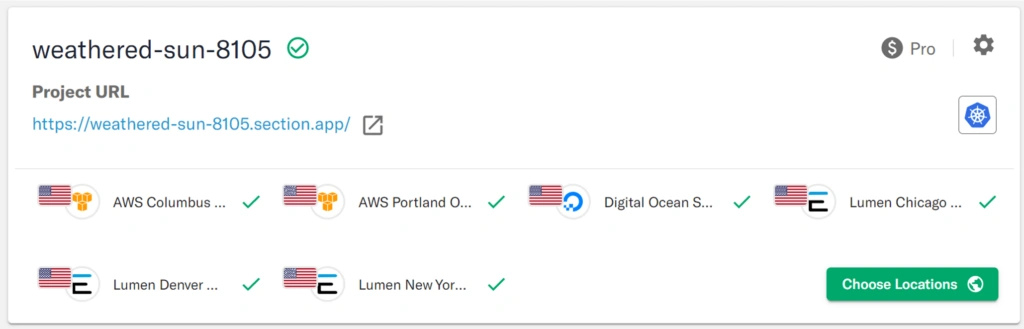
Again, without any operations activity, other than selecting the locations,
- CloudFlow sets the networking (DNS, Anycast, SSL Management, DDoS Scrubbing, etc) to route traffic to all these locations and sends traffic to the best available location automatically
- The Nginx container is deployed to all these locations and each starts serving traffic
- The Fluent D container is deployed to all these locations and each starts sending logs to the central collation point – ie New Relic
Immediately we see a performance improvement for users in the Western parts of North America in the order of 5 to 6 times better!
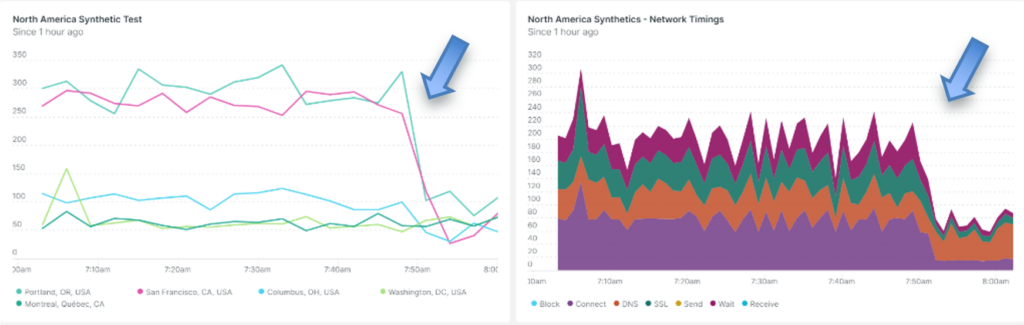
However, we can also see that the European users and those in Asia/ ROW are still experiencing a sub-standard experience. (we did see a moderate improvement in user experience in Asia thanks to the closer proximity of US West locations)
Distributing the Application Using CloudFlow’s AI/ML automation
So what if we let CloudFlow’s Adaptive Edge Engine (AEE) take control of the application placement and simply deploy the application to the best locations for the application at any point in time?
By turning on Automatic optimization in the CloudFlow Console, the application will be placed into endpoints across the world to optimize for latency.

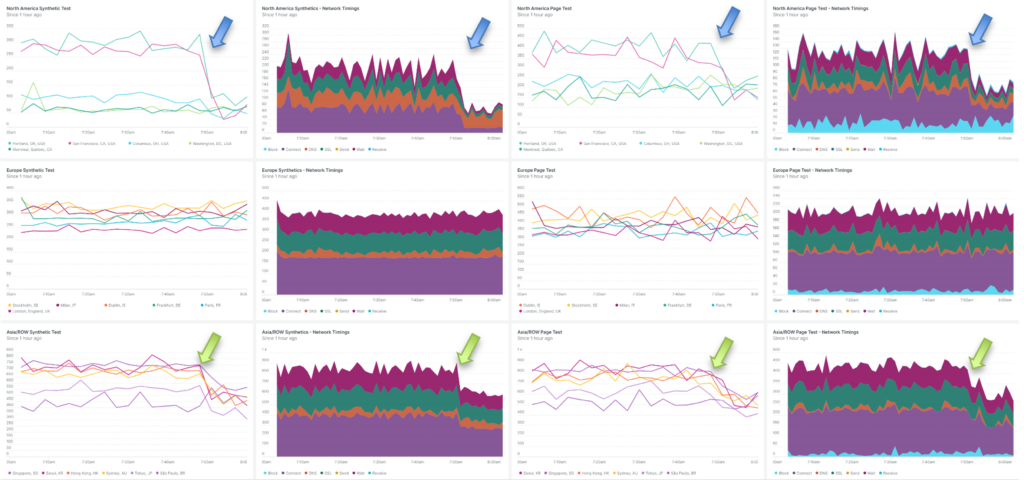
With all locations across the globe generating traffic at this time, the CloudFlow’s AEE reconfigured the deployment footprint of this application in 10 minutes to run in the following locations:
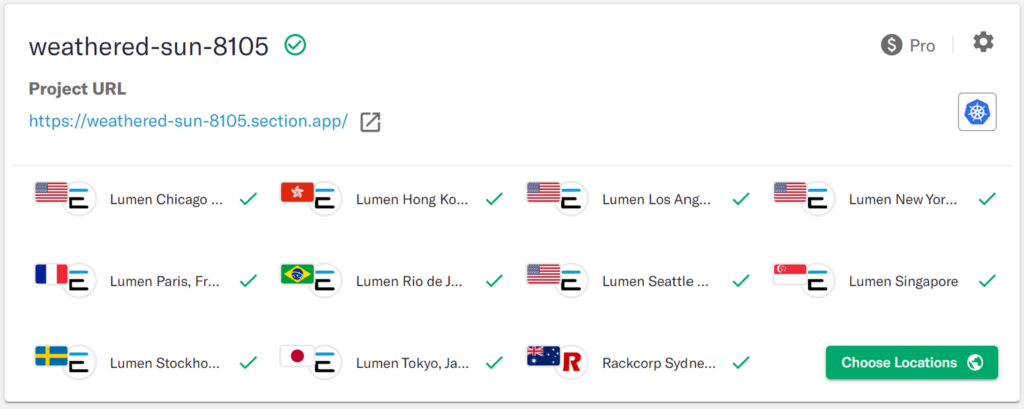
And as we expect, user experience all over the globe is significantly improved.
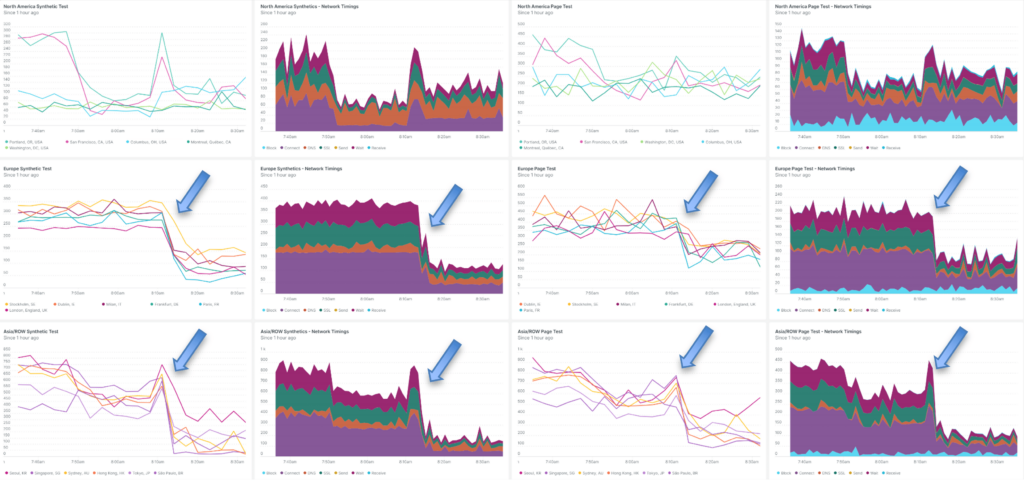
Of note, the AEE decided that to find the optimal balance between locations utilized (i.e. cost) and performance, fewer locations in North America were needed than the 6 we manually selected. It chose Seattle and Los Angeles for the Western locations. We can also see a short slight increase in request time while the new Western North American locations were brought into service and the others removed.
Importantly, no requests were dropped by the distributed hosting footprint during this automated adaptation of the network footprint.
Distributing the Application Dynamically
So we know that in the real world, traffic ebbs and flows throughout any 24-hour period and indeed week to week or month to month. Why should we keep all these global locations operating at all times? What happens if traffic dissipates from some locations? Say, it’s late at night in North America.
Real Internet application traffic is not stagnant so our hosting resources should not be stagnant
The Automatic Optimization of CloudFlow’s AEE is constantly refining placement decisions based on a myriad of ingested data feeds. The AEE will detect a traffic change and then, in minutes, re-optimize the footprint for performance.
To test this we turned off all the monitors emanating from North America. In response, the AEE then decided the following locations make sense in the absence of traffic from North America.
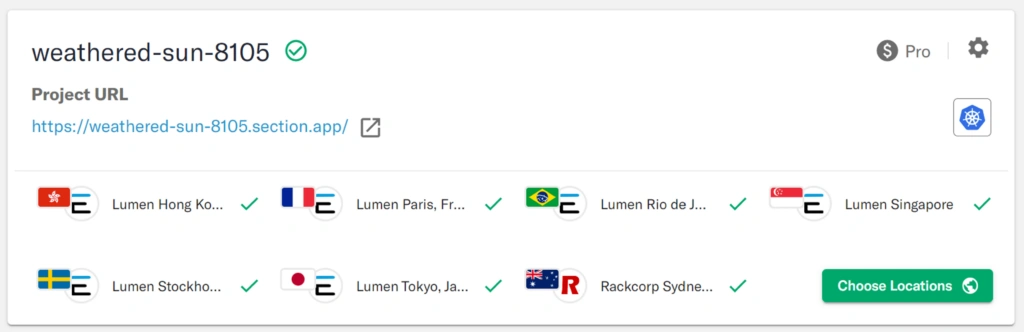
The Adaptive Enge Engine again reshaped the delivery network by withdrawing unneeded locations. All without dropping any requests from any location.
The following shows the traffic performance from each location in the absence of any traffic from North America.
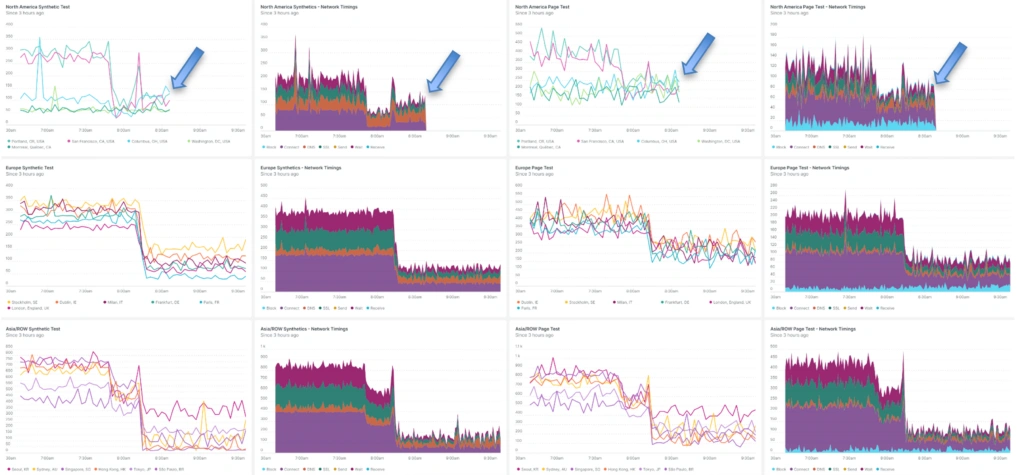
Let’s check if the CloudFlow can detect an increase in traffic from any location and how the Adaptive Edge Engine responds in order to continuously adapt and deliver optimal placement for user experience.
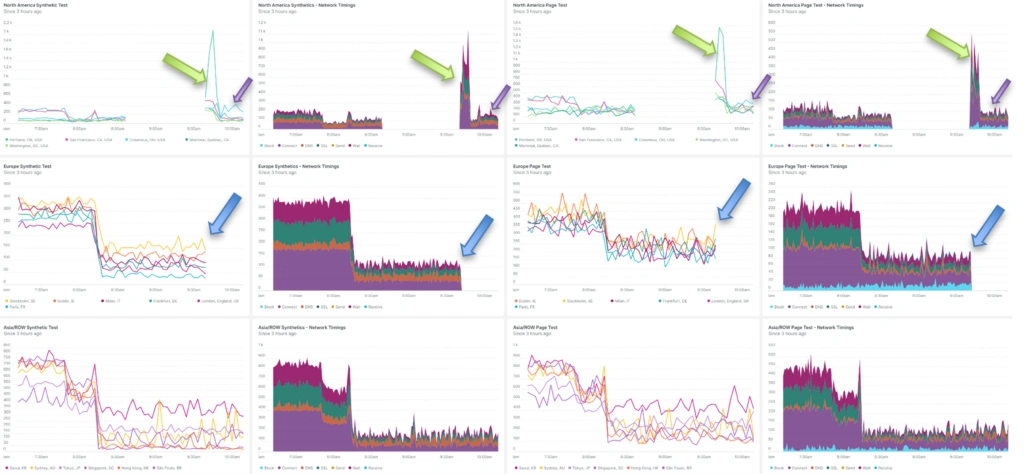
Let’s say the traffic increases from North America and at the same time, traffic from Europe dissipates.
In 10 minutes, the AEE shifts the application around, bringing it up in North America and removing the unneeded locations in Europe. Again, of note, no requests are dropped through the period. The AEE routes North American requests to the next best location while the application is in the 10-minute deploy period to the North American PoPs.
During the deploy period;
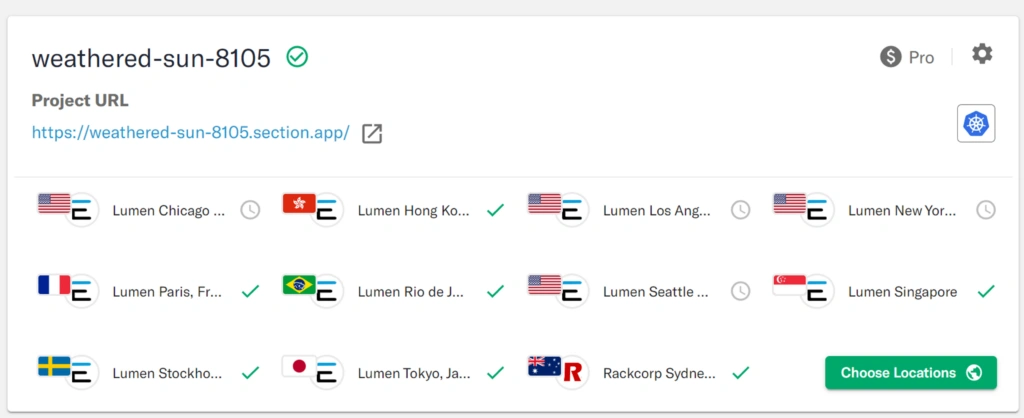
Post Deploy period:
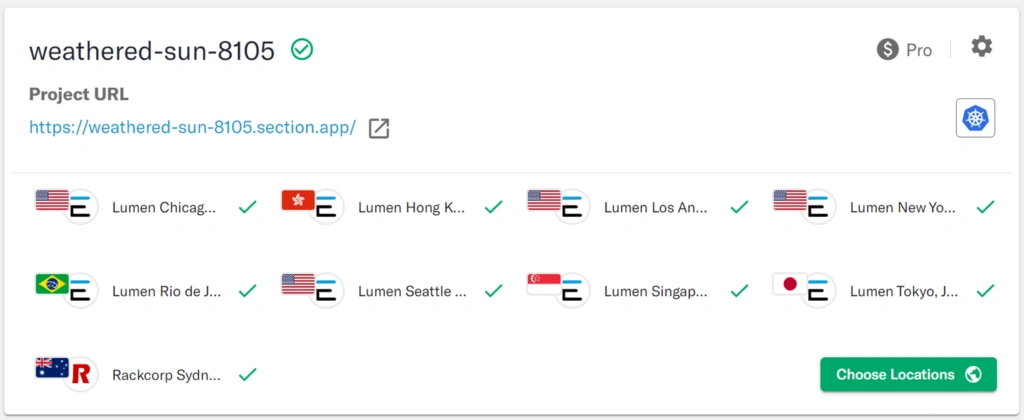
As the traffic from North America is detected, it is immediately routed to the next best location until the North American locations are available. When the AEE detects those locations are up and ready to receive traffic, the AEE starts sending traffic there and then user experience in North America is again optimal. All this happens constantly, automatically, and transparently to the operations teams and the end users.
Cost Optimization
This adaptive, “run only where you need to” behavior allows for cost as well as user experience optimization. We do not need to run the application in every location at all times as would otherwise be the case in the absence of the Auto Optimization capabilities of CloudFlow’s Adaptive Edge Engine.
What have Ops been Doing?
It is worth noting for each of the distribution methods discussed above, there has been no change to the core development or operational practices for the application.
Logs continue to stream to a central location, the team can SSH into any delivery box at any time and the Dev team can continue to develop the application in the same way they always have.







