





Last week we published Part 1 of a two-part series on the benefits of distributed multi-cluster deployments for modern application workloads, based on our white paper that dives deep into these topics. This is part two. The context for this discussion is the breakthrough Kubernetes Edge Interface, which makes it incredibly easy to move workloads to the edge using familiar tools and processes, and then manage that edge deployment with simple policy-based controls.
But why move to the edge if you’ve already got a centralized data center or cloud deployment? If you haven’t read the first three benefits in the previous post, please take a moment to do so. Here are four more.
Scalability
In our previous post, we noted that improvements to performance and latency are a key benefit of moving application workloads to the edge (compared to centralized cloud deployments). A closely related factor: running multiple distributed clusters also improves an organization’s ability to fine tune and scale workloads as needed. This scaling is required when an application can no longer handle additional requests effectively, either due to steadily growing volume or episodic spikes.
It’s important to note that scaling can happen horizontally (scaling out), by adding more machines to the pool of resources, or vertically (scaling up), by adding more power in the form of CPU, RAM, storage, etc. to an existing machine. There are advantages to each, and there’s something to be said for combining both approaches.
A distributed multi-cluster topology helps facilitate greater flexibility in scaling. Among other things, when run on different clusters/providers/regions, it becomes significantly easier to identify and understand which particular workloads require scaling (and whether best served by horizontal or vertical scaling), whether that workload scaling is provider- or region-dependent, and ensure adequate resource availability while minimizing load on backend services and databases.
Those familiar with Kubernetes will recognize that one of its strengths is its ability to perform effective autoscaling of resources in response to real time changes in demand. Kubernetes doesn’t support just one autoscaler or autoscaling approach, but three:
- Pod replica count – This involves adding or removing pod replicas in direct response to changes in demand for applications using the Horizontal Pod Autoscaler (HPA).
- Cluster autoscaler – As opposed to scaling the number of running pods in a cluster, the cluster autoscaler is used to change the number of nodes in a cluster. This helps manage the costs of running Kubernetes clusters across cloud and edge infrastructure.
- Vertical pod autoscaling – the Vertical Pod Autoscaler (VPA) works by increasing or decreasing the CPU and memory resource requests of pod containers. The goal is to match cluster resource allotment to actual usage.
Worth noting for those running centralized workloads on single clusters: a multi-cluster approach might become a requirement for scaling if a company’s application threatens to hit the ceiling for Kubernetes nodes per cluster, currently limited to 5,000.
Cost
Another advantage to a distributed multi-cluster strategy is fine-grained control of costly compute resources. As mentioned above, this can be time-dependent, where global resources are spun down after hours. It can be provider-dependent, where workloads can take advantage of lower cost resources in other regions. Or it can be performance-dependent, whereby services that aren’t particularly sensitive to factors like performance or latency can take advantage of less performant, and less costly, compute resources.
Isolation
A multi-cluster deployment physically and conceptually isolates workloads from each other, blocking communication and sharing of resources. There are several reasons this is desirable. First, it improves security, mitigating risk by limiting the ability of a security issue with one cluster to impact others. It can also have implications for compliance and data privacy (more on that below). It further ensures that the compute resources you intend for a specific cluster are, in fact, available to that cluster, and not consumed by a noisy neighbor.
But by far the most common rationale behind workload isolation is the desire to separate development, staging/testing and production environments. By separating clusters, any change to one cluster affects only that particular cluster. This improves issue identification and resolution, supports testing and debugging, and promotes experimentation and optimization. In short, you can ensure a change is working as expected on an isolated cluster before rolling it into production.
As noted, this isolation is an inherent benefit of multi-cluster vs single cluster deployments, and not particularly dependent on how widely distributed those clusters are – you could have isolated stage/test/production clusters in a centralized hosting environment, for example. That said, when you distribute multiple clusters, this isolation can have important implications.
Compliance Requirements
Compliance is a critical consideration for many organizations. It can be closely related to isolation – workload isolation is required for compliance with standards such as PCI-DSS, for example – but it also has broader implications in regard to distributed or multi-region workloads.
In this instance, different countries and regions have unique rules and regulations governing data handling, and a distributed multi-cluster topology facilitates a region-by-region approach to compliance. A notable example is the European Union’s General Data Protection Regulation (GDPR), which governs data protection and privacy for any user that resides in the European Economic Area (EEA). Importantly, it applies to any company, regardless of location, that is processing and/or transferring the personal information of individuals residing in the EEA. For instance, GDPR may regulate how and where data is stored, something that is readily addressed through multiple clusters.
Similarly, other regulatory or governance requirements might stipulate that certain types of data or workloads must remain on-premises; a distributed multi-cluster topology allows an organization to meet this requirement while simultaneously deploying clusters elsewhere to address other business needs (to the edge for lower latency, for example).
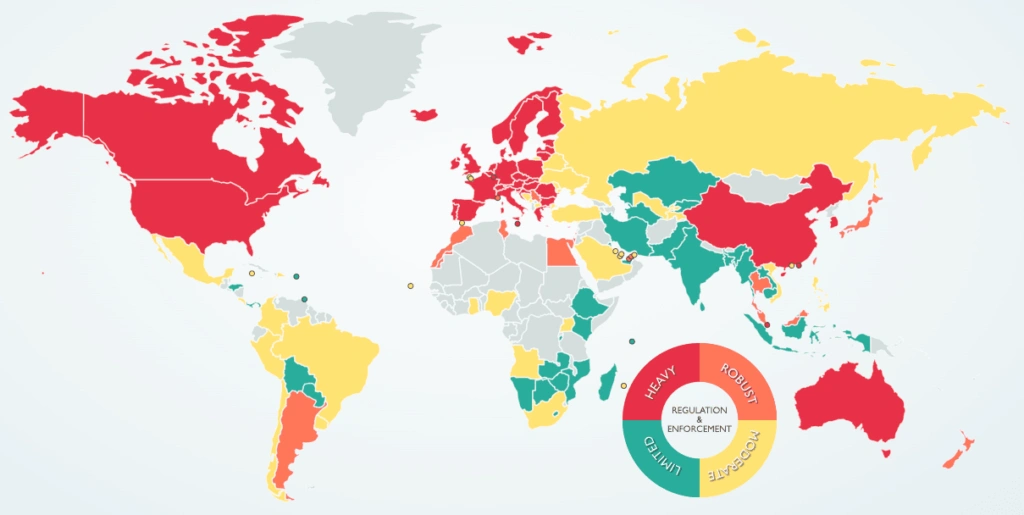
Image source: DLA Piper Data Protection Laws of the World interactive tool
So there you have it, seven key benefits of edge deployments:
- Improved Availability and resiliency
- Avoiding vendor lock-in
- Better performance and latency
- Greater scalability
- Lower cost
- Increased workload isolation
- Flexible compliance
Ready to see how easy it is to move your workloads to the edge with Webscale CloudFlow’s revolutionary Kubernetes Edge Interface? Request a demo.







